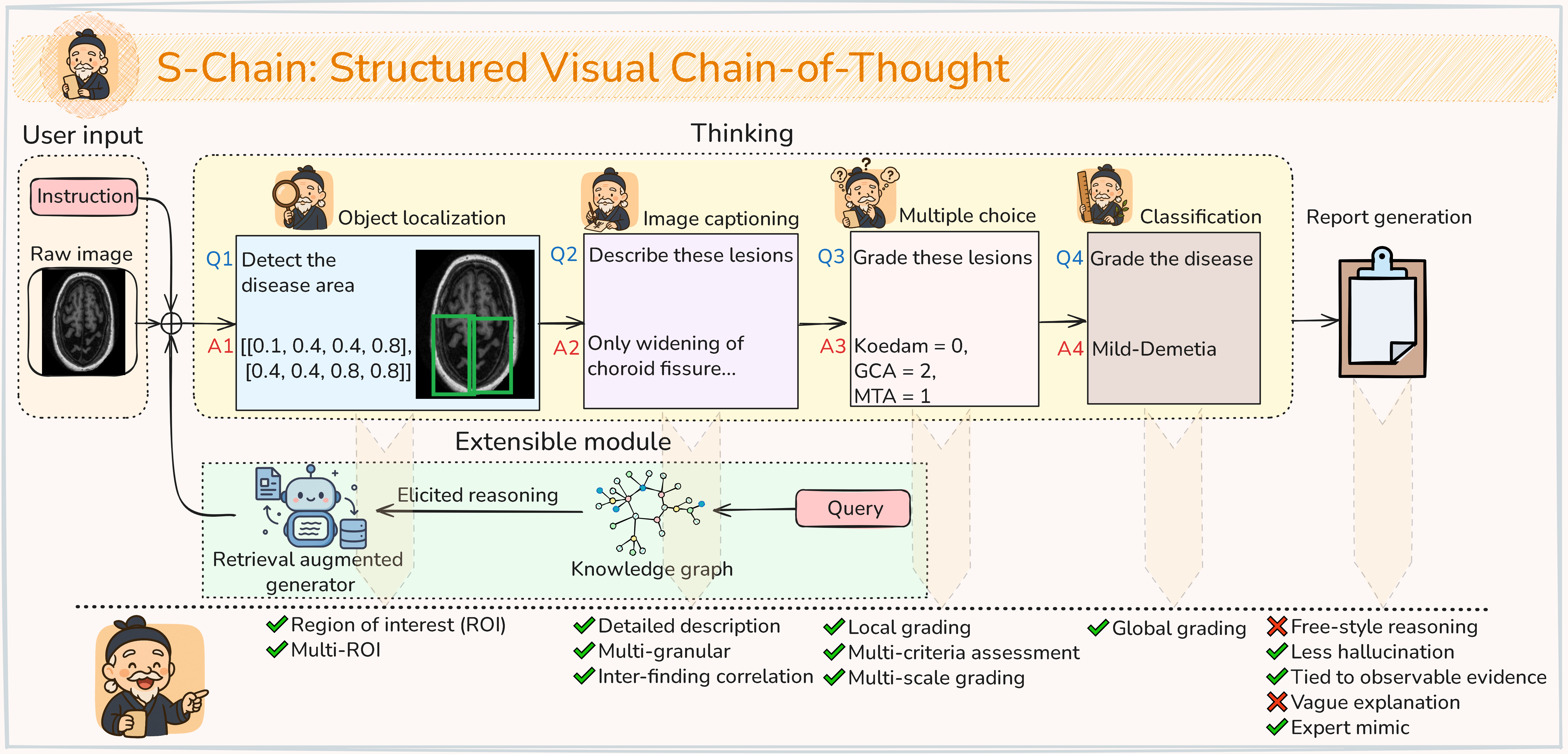
Faithful reasoning in medical vision–language models (VLMs) requires not only accurate predictions but also transparent alignment between textual rationales and visual evidence. While Chain-of-Thought (CoT) prompting has shown promise in medical visual question answering (VQA), no large-scale expert-level dataset has captured stepwise reasoning with precise visual grounding. We introduce S-Chain, the first large-scale dataset of 12,000 expert-annotated medical images with bounding-boxes and structured visual CoT (SV-CoT), explicitly linking visual regions to reasoning steps. The dataset further supports 16 languages, totaling over 700k VQA pairs for broad multilingual applicability. Using S-Chain, we benchmark state-of-the-art medical VLMs, showing that SV-CoT supervision significantly improves interpretability, grounding fidelity, and robustness. S-Chain establishes a new benchmark for grounded medical reasoning and paves the way toward more trustworthy and explainable medical VLMs.
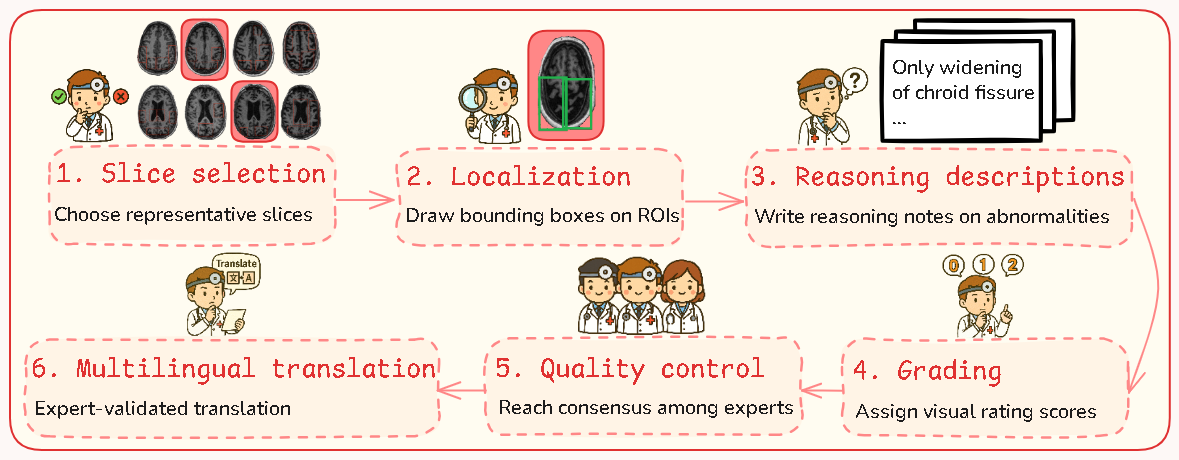
Our dataset was meticulously created through a six-step annotation pipeline involving three trained doctors and professional linguists, requiring over 700 hours of expert labor.
The dataset is built from the OASIS MRI dataset and is split to ensure no patient overlap between the training and testing sets, with a distribution that mirrors real-world clinical cohorts. S-Chain supports 16 languages: English, French, German, Japanese, Korean, Mandarin, Portuguese, Spanish, Italian, Dutch, Russian, Arabic, Hindi, Vietnamese, Thai, and Indonesian, enabling broad multilingual applicability in medical AI systems.
| Split | # Images | # QA pairs | # Patients | Non-Dementia | Mild-Dementia | Mod-Dementia |
|---|---|---|---|---|---|---|
| Train | 10,783 | ~690k | 55 | 4,628 | 4,755 | 1,400 |
| Test | 1,542 | ~98k | 9 | 562 | 420 | 560 |
| Total | 12,325 | ~788k | 64 | 5,190 | 5,175 | 1,960 |
S-Chain provides structured visual chain-of-thought reasoning across multiple languages, ensuring global accessibility and applicability in diverse medical contexts. Here are 4 example representations showcasing the dataset's multilingual capabilities:
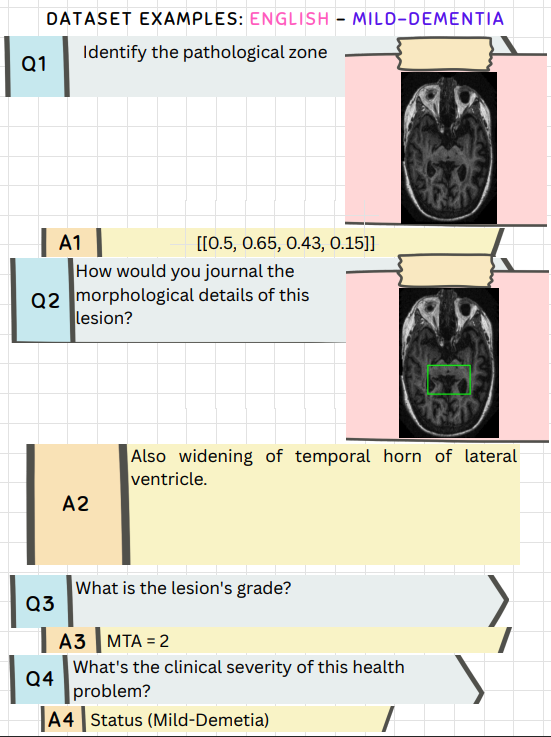
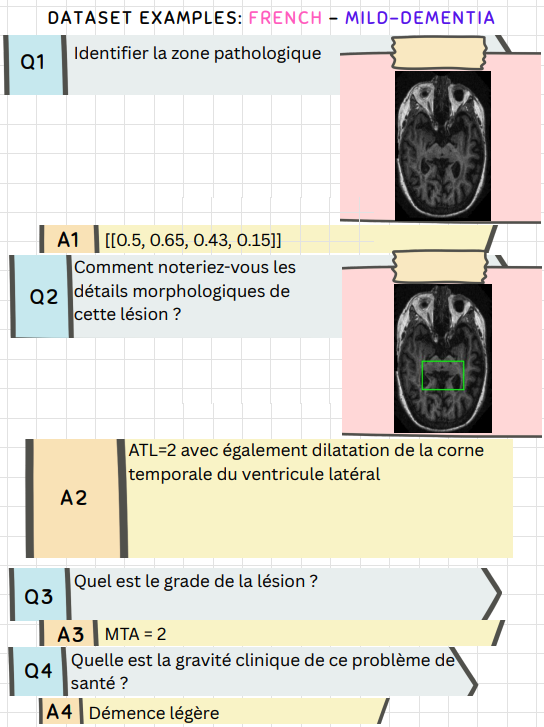
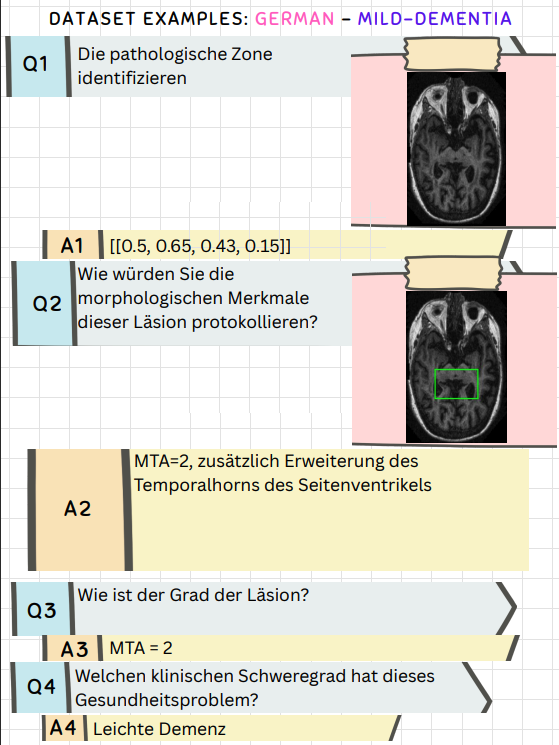
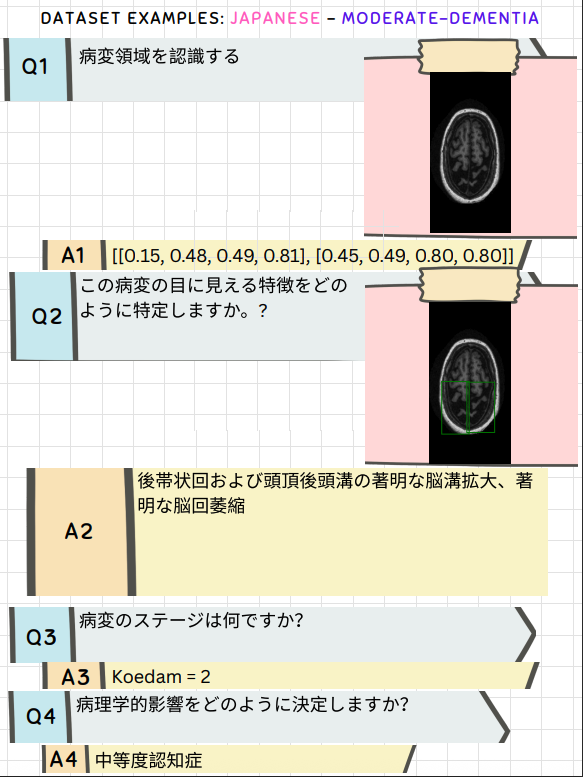
Try S-Chain! Select an image to see different aspects of our structured visual chain-of-thought approach.
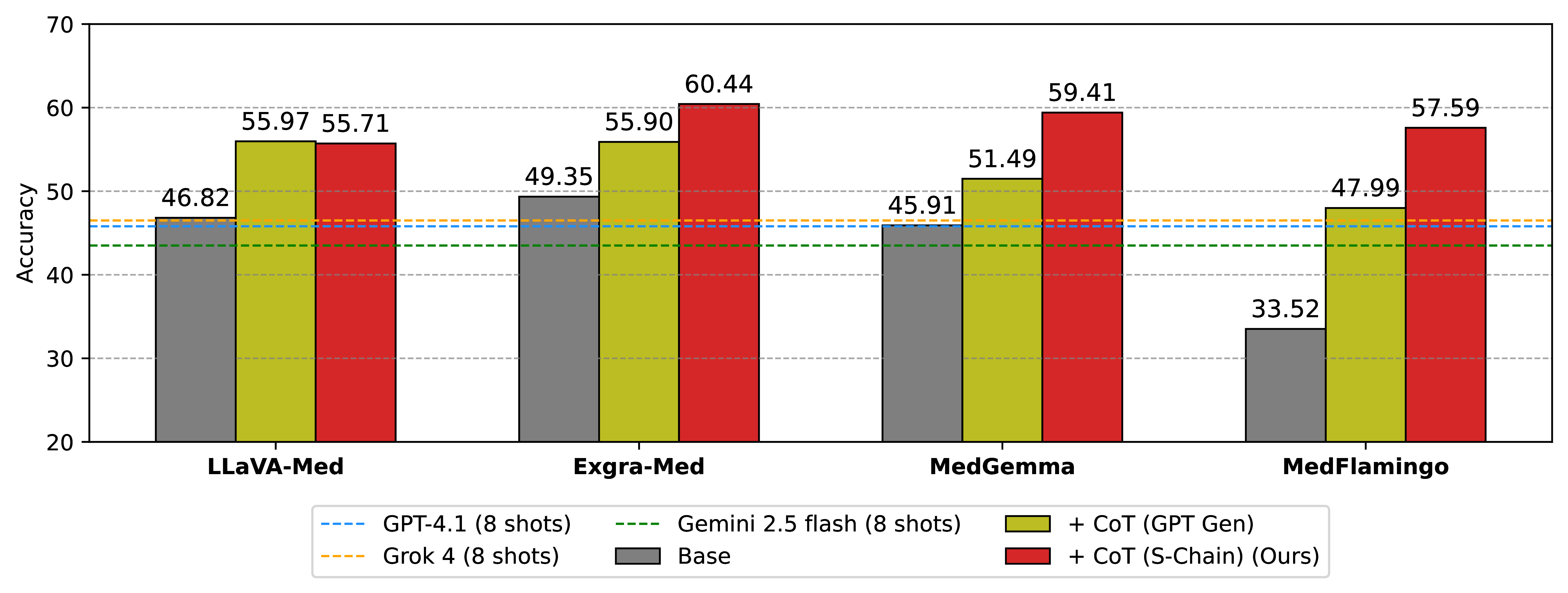
A core finding of our work is that expert-annotated, structured data is crucial for reliable medical reasoning. Models trained with S-Chain consistently outperform baselines trained on synthetic CoTs generated by GPT-4.1 by 4-5%.
Synthetic data often suffers from hallucinations, such as incorrect or missing bounding boxes, which undermines the model's ability to ground its reasoning in visual evidence.
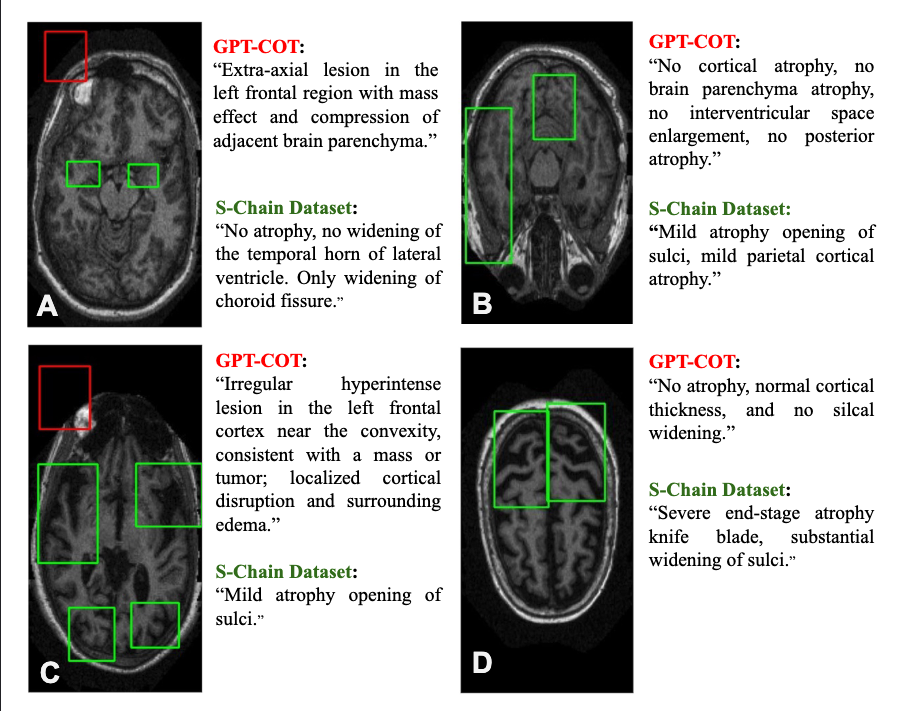
Red: GPT-4.1 hallucinates an "extra-axial lesion" that is not present. Green: The S-Chain annotation correctly identifies "no atrophy".
While S-Chain provides strong visual grounding, we found that combining it with external medical knowledge via Retrieval-Augmented Generation (RAG) yields the best performance.
| Model | Base (Acc / F1) | + MedRAG | + SV-CoT | + SV-CoT + MedRAG | |||
|---|---|---|---|---|---|---|---|
| Score | Δ | Score | Δ | Score | Δ | ||
| ExGra-Med | 49.4 / 46.9 | 50.3 / 48.7 | +0.9 / +1.8 | 60.4 / 59.6 | +11.0 / +12.7 | 64.8 / 62.6 | +15.4 / +15.7 |
| LLaVA-Med | 46.8 / 43.2 | 50.8 / 48.9 | +4.0 / +5.7 | 55.7 / 53.0 | +8.9 / +9.8 | 59.5 / 57.8 | +12.7 / +14.6 |
| MedGemma | 45.9 / 42.1 | 47.6 / 44.4 | +1.7 / +2.3 | 59.4 / 56.7 | +13.5 / +14.6 | 56.7 / 52.9 | +10.8 / +10.8 |
| Qwen2.5-VL | 50.5 / 45.6 | 54.3 / 54.2 | +3.8 / +8.6 | 55.0 / 49.4 | +4.5 / +3.8 | 60.8 / 47.9 | +10.3 / +2.3 |
| InternVL2.5 | 50.5 / 47.6 | 52.3 / 43.3 | +1.8 / -4.3 | 53.4 / 48.8 | +2.9 / +1.2 | 58.3 / 54.6 | +7.8 / +7.0 |
A. Component-wise Reasoning Analysis. Experiments on the S-Chain dataset show that providing ground-truth ROIs yields small gains in diagnostic accuracy, but adding correct chain-of-thought (CoT) steps nearly solves the task, reaching 99% accuracy. This shows that accurate intermediate reasoning makes final predictions almost trivial, highlighting the importance of structured supervision over end-to-end training for interpretable and reliable medical vision-language models.
B. Bounding Boxes and Grounded Reasoning. To study how ROI representations affect visual reasoning, we compare two grounding strategies: 1. textual supervision: encodes bounding box coordinates in the training text, and 2. visual prompting: highlights ROIs directly on the image. We further test how perturbing or removing ROI information impacts the accuracy and alignment of chain-of-thought (CoT) reasoning with visual evidence.
Findings: Visual prompting better anchors reasoning to true abnormalities (0.73 Acc) than textual supervision (0.62 Acc), leading to more faithful and clinically grounded CoTs.
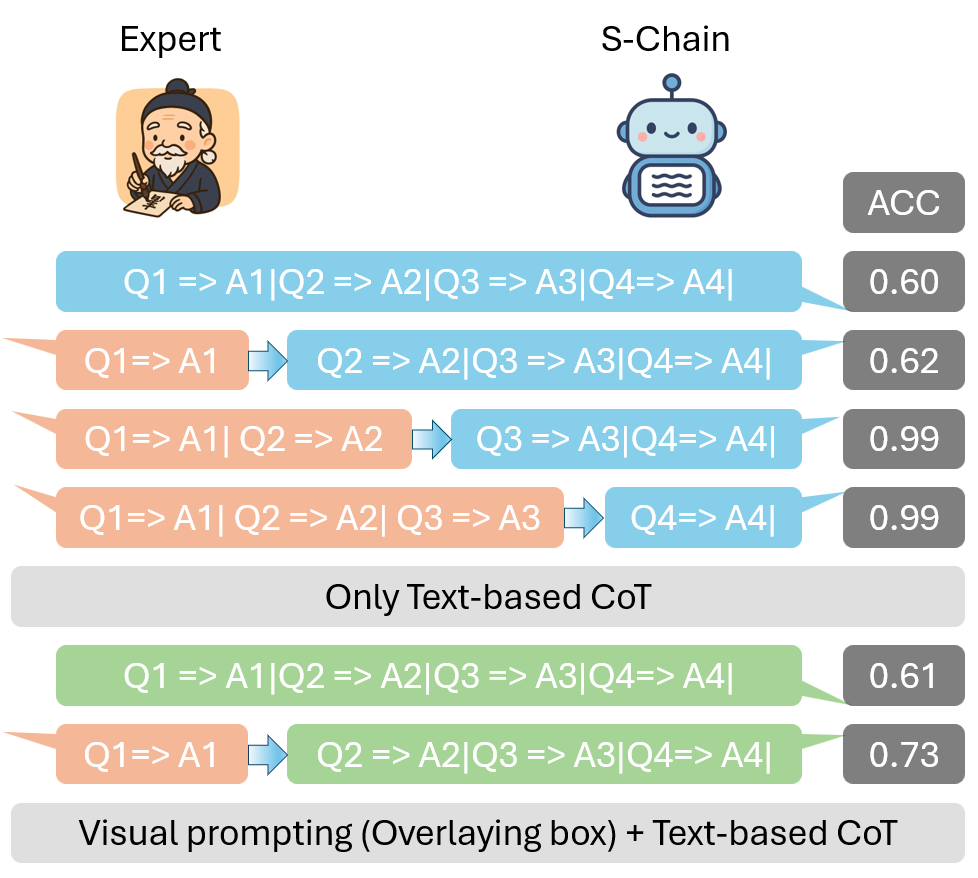
Light peach blocks show ground-truth inputs at test time, while blue/green blocks are model-generated. Upper settings use text-based CoTs, and lower settings use visual prompting to ground reasoning in ROIs.
C. Towards Faithful Vision-Language Reasoning. We found that models can generate plausible reasoning without truly attending to the intended visual regions. To address this, we introduced a training strategy that explicitly aligns the model's CoT with visual tokens from the correct ROIs. This lightweight regularization improves ExGra-Med's accuracy from 60.4% to 62.5% and F1 from 59.6% to 61.7%. While the gains are modest, they underscore that enhancing CoT–ROI alignment is a promising step toward more faithful multimodal reasoning, with its optimal enforcement remaining an open challenge for future research.
While S-Chain is a significant step forward, we acknowledge its limitations. The dataset currently has limited diagnostic coverage and follows a linear reasoning path that simplifies complex clinical workflows.
Future work should focus on expanding the dataset and developing more advanced models. Key research directions include large-scale grounded pre-training, new cross-modal contrastive objectives, and faithful decoding strategies to ensure VLMs are not only accurate but truly clinically trustworthy.
@misc{leduc2024schain,
title={S-Chain: Structured Visual Chain-of-Thought for Medicine},
author={Khai Le-Duc and Phuong T. H. Trinh and Duy M. H. Nguyen and Tien-Phat Nguyen and Nghiem T. Diep and An Ngo and Tung Vu and Trinh Vuong and Anh-Tien Nguyen and Mau Nguyen and Van Trung Hoang and Khai-Nguyen Nguyen and Hy Nguyen and Chris Ngo and Anji Liu and Nhat Ho and Anne-Christin Hauschild and Khanh Xuan Nguyen and Thanh Nguyen-Tang and Pengtao Xie and Daniel Sonntag and James Zou and Mathias Niepert and Anh Totti Nguyen},
year={2024},
eprint={...},
archivePrefix={arXiv},
primaryClass={cs.CV}
}








